Midterms are on the horizon. Can election models actually predict who will win?

Share

The election modelers of the world have a tough job. They’re relied on to offer election predictions months and sometimes years in advance of national contests that many people, from mainstream pundits to the candidates themselves, live and die by. Consequently, so do the modelers.
But just how accurate are election forecasts? With election observers increasingly pinning their hopes on crystal ball types like Nate Silver, who came to prominence after successfully predicting former president Barack Obama’s victories in every U.S. state in 2008 and 2012, errant results can derail mainstream storylines and reveal biases.
The 2016 presidential election is a good example of this, when Silver’s modeling outfit FiveThirtyEight, along with numerous other state, federal and independent election data sources, greatly overestimated support for Hillary Clinton (of course, as it turned out, she did win the popular vote). Silver appeared to take the fall for his colleagues, writing in a lengthy election retrospective about the “challenges of poll interpretation” and the “pervasive groupthink among media elites.”

“After Trump’s victory, the various academics and journalists who’d built models to estimate the election odds engaged in detailed self-assessments of how their forecasts had performed,” Silver wrote in the 2016 election post-mortem. “Most of these mistakes were replicated by other mainstream news organizations, and also often by empirically minded journalists and model-builders.”
Fast-forward to 2022, and FiveThirtyEight is still the leading modeling source in the election prediction game, says Nick Beauchamp, associate professor of political science at Northeastern. The site has put out its 2022 midterm predictions, rating each party’s chances of gaining or losing seats based on a likelihood scale—categorizing them, for one or another party, as either solid, likely, leaning or a toss-up.
FiveThirtyEight is also offering predictions of individual races. But Beauchamp says there are reasons to be skeptical of those models.
“If you read the very fine print of those models, you discover that they’re mostly using the generic ballot score plus the partisan lean of each state or district —and those two factors are doing almost all of the work in their models,” he says.
The generic ballot, often considered one of the most reliable sources in predicting presidential and congressional races, is a poll that measures support on the basis of party, rather than specific candidates. There are other factors that should be considered, such as historical trends and developments in the news that have an outsized, and perhaps unexpected, impact on voters and their opinions, Beauchamp says.
During this year’s election cycle, political observers have cited the Supreme Court’s decision to overturn abortion rights as the issue likely to skew the models.
“What makes a lot of these models problematic is that there always are new and idiosyncratic factors that enter in that weren’t taken into account in past models because they never really had any impact,” Northeastern political science professor William Mayer says. “A good example of this is the abortion issue.”
Another notable wildcard forecasters have to take into account when interpreting election data is the ever-evolving influence of former president Donald Trump, whose endorsements have in many cases served to elevate unconventional candidates, such as Herschel Walker, a former football star who became Georgia’s Republican nominee for U.S. Senate, and Mehmet Oz, a former TV personality who is running in Pennsylvania for a U.S. Senate seat.
History would dictate that, under ordinary circumstances, Walker and Oz would be considered “weak” picks for high office, Mayer says. The criteria of assessing candidate competency has shifted as a result. It’s just another example of the “Trump effect,” and the norm-shattering impact the former president has had on U.S. electoral politics.
Next month, Beauchamp and Mayer will be presenting models that offer midterm predictions, with an emphasis on the House races, at the Political Science Association. Mayer is predicting that the Democrats will lose up to 40 seats in the House; Beauchamp’s outlook is less austere.
“The models I have played around with over the last six months or so are based on two major variables. One is presidential popularity, and the other is how many seats the party of the president holds relative to its long-run average,” Mayer says.
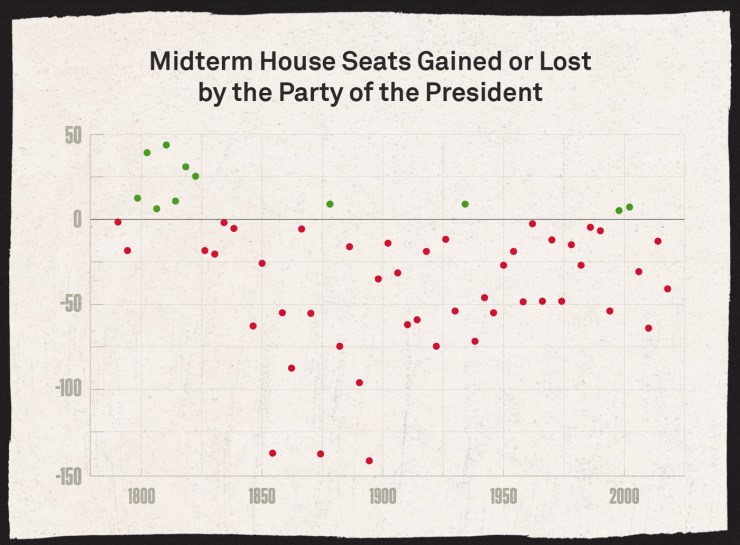
Since the Democratic and Republican parties began to entrench themselves politically in the U.S., there has been a pretty consistent trend of the presidential party losing a chunk of seats in the House of Representatives during the midterms, Beauchamp says. Historical precedents like this are sometimes overlooked in election models.
“To a first approximation, predicting how the midterms are going to turn out is one of the boringest prediction jobs you can have in political science,” Beauchamp says. “That’s because we don’t have too many regularities, but the one that is most certain is that the president’s party usually loses seats in both chambers during the midterms.”
The Senate is more difficult to model—and this election cycle is no exception, Beauchamp says.
“We could say of the Senate we’re much more uncertain this time around than many times we’ve been in the past,” he says.
For media inquiries, please contact media@northeastern.edu.





