This researcher put AI in the big game. It did not play well
Northeastern professor Lorenzo Torresani is interested in developing AI that can make sense of challenging group activities.


A researcher analyzing reams of data. A traveler translating a foreign language. A student writing an essay. There are many ways that artificial intelligence has been proven to help an individual in a challenging situation.
Northeastern University researcher Lorenzo Torresani wanted to test whether AI can help a group facing a challenge, and he found an interesting dataset with which to evaluate various popular AI models: sports footage.
The result? Let’s just say the AI models were no slam dunk.
“AI can really describe what people do and where they go when they perform an action – even on the pitch or on the court,” said Torresani, professor and President Joseph E. Aoun chair in the Khoury College of Computer Sciences at Northeastern. “It cannot tell you why things happen, and it cannot tell you what’s gonna happen next.”
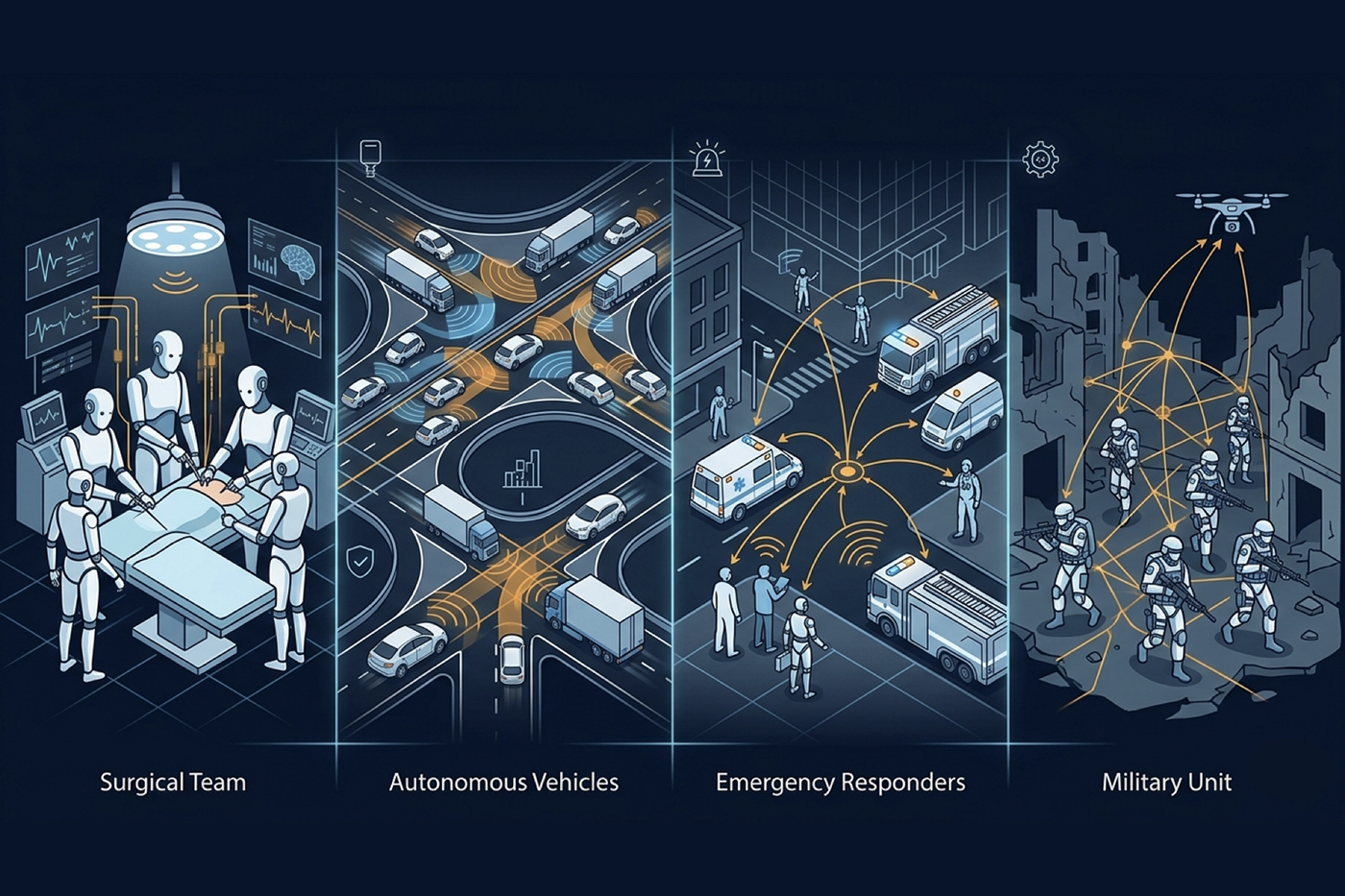
Torresani is interested in developing AI that can make sense of challenging group activities where multiple people are working together in a dynamic environment and coordinating their efforts toward a goal. Often, those environments have many unknowns and preclude extensive verbal communication. For example, he wanted to know whether AI could help a surgery team in the operating room, a group of first responders on the scene of an emergency, or a military unit in action by proposing and then evaluating potential actions and predicting outcomes, among other things.
“So, [situations where] a lot needs to be inferred from the actions, rather than verbally,” Torresani said.
Northeastern Global News, in your inbox.
Sign up for NGN’s daily newsletter for news, discovery and analysis from around the world.
He found that AI models have not been really trained or tested in such scenarios because of a lack of data. Plus, he said, how do you objectively identify and test a concept like cause-and-effect?
“We humans have developed cause-and-effect reasoning over many, many years, since we were kids,” Torresani said. “But labeling something as a cause and as an effect, is very subjective and challenging in the real world.”
Smit Desai, an assistant professor of art and design and communication studies and director of the Conversational Human-AI Interactions (CHAI) Lab, which studies how people understand, trust, and collaborate with conversational AI, said finding datasets to test advanced AI concepts is “definitely a challenge.”
“Evaluating advanced AI capabilities like agency, planning, or causal reasoning is difficult because these behaviors are often highly context-dependent,” Desai said.
Desai explained that many datasets and evaluation tasks that we rely on today were designed for simpler, more narrowly defined tasks with a clearly defined correct answer – for example, a model might be asked to answer a factual question, solve a math problem, or identify an object in an image.
But tasks involving agency, planning, causal reasoning, or social intelligence are often more difficult to evaluate because there may not be a single correct answer, he said.
“Performance can depend heavily on context, long-term outcomes, or human judgment,” Desai said.
So, Torresani turned to an arena that’s rife with group work: Team sports.
Torresani and professor Gedas Bertasius at UNC Chapel Hill, built a dataset with 35,000 hours of videos of hockey, basketball and soccer games along with 23,000 game reports from journalists and 15,000 hours of expert commentary.
The dataset is publicly available as an open resource for the community.
“They provide lots of examples, one after another, of cause-and-effect,” Torresani said. “They also have verifiable outcomes.”
For example, Torresani explained that researchers can query AI models about certain plays or actions and then can check their answers with what actually happened – did AI models correctly predict that a team would lose possession of the ball or was the model wrong and the team maintained possession? Did a sequence of plays the model analyzed and based predictions on lead to scoring, or a failed shot, or a turnover? Did the model analyze all the data and correctly predict the winner?

The researchers put popular AI models, including GPT and Gemini to the test.
Editor’s Picks





The researchers evaluated the models on four different capabilities: perception, causal reasoning, counterfactual simulation and agency.
AI models did well on perception, correctly identifying who does what, when and where about 74% of the time, according to the research.
Causal reasoning (explaining what caused a certain event) and counterfactual simulation (if I did this instead, what would happen) was accurate about 40% to 50% of the time.
The success rate for agency, or asking AI to find evidence from clips to answer complex questions; however, was only 5%. For example, the models were asked to analyze video, play-by-play accounts and game stories by journalists up to specific points in the game – say just before the end of each quarter of a basketball game – and predict who would ultimately win. Only at the very end of the game were the predictions accurate.
In other words, AI is probably not coming for sportscasters anytime soon.
“A good sportscaster does much more than describe what’s on screen – they explain why a play worked, anticipate what’s next, and (perhaps most importantly) decide which moments matter,” Torresani said. “Our study shows AI is already reasonably good at the descriptive part, but collapses on the rest.”
This limitation also goes beyond sports, Torresani said.
“The same gap shows up in any job whose value lies not in describing what’s visible, but in understanding why events unfold, anticipating what comes next, deciding what matters, and recommending what to do about it,” Torresani said.





